Building Workflows
Building Workflows
The input parameters that appear in the Run Workflow tab are defined by a YAML (.yaml) file. The YAML for local workflows is stored by the platform, so you can view and edit the YAML directly by using the Build tab. From there, you can define the jobs and inputs for your workflow.
YAML syntax
Since the workflows on ACTIVATE are written in YAML, it's worthwhile to get a grasp on YAML basics before diving into building workflows. For a quick overview, check out the Red Hat website.
Navigate to Workflows > your workflow > the Build tab.
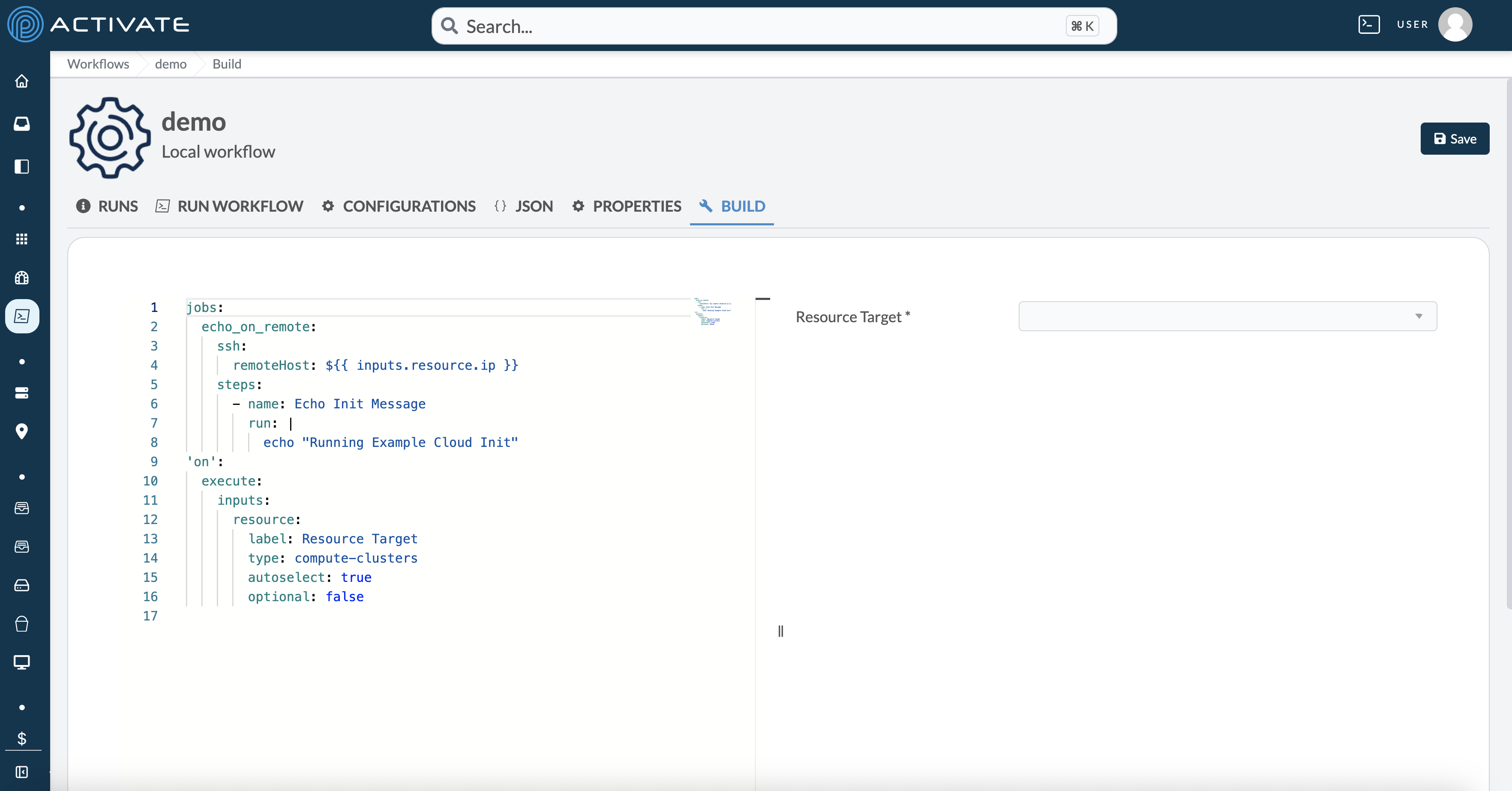
Newly created local workflows are loaded with a default YAML file configuration, as seen in the screenshot below.
Workflow Builder Tips
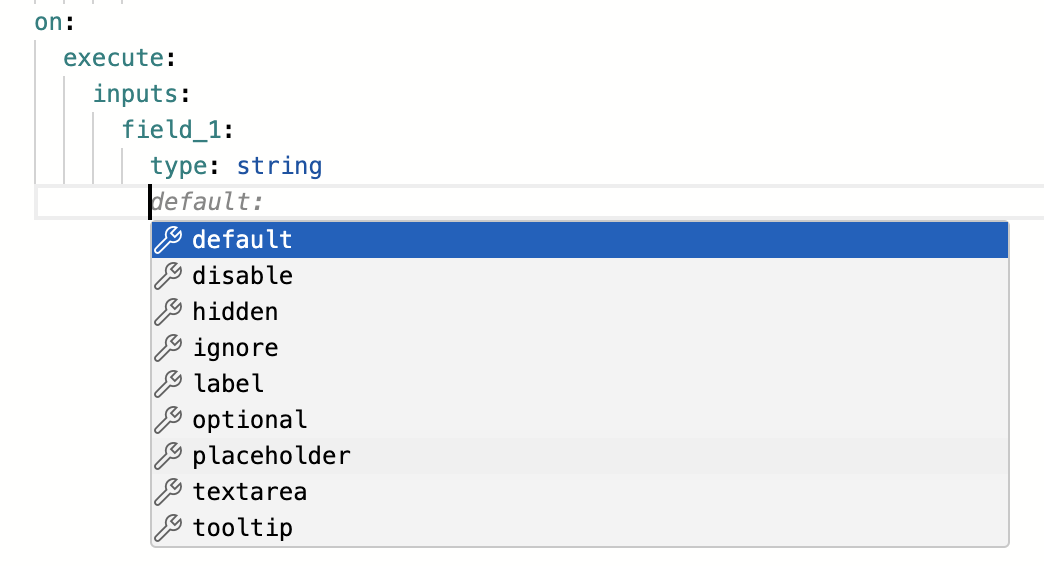
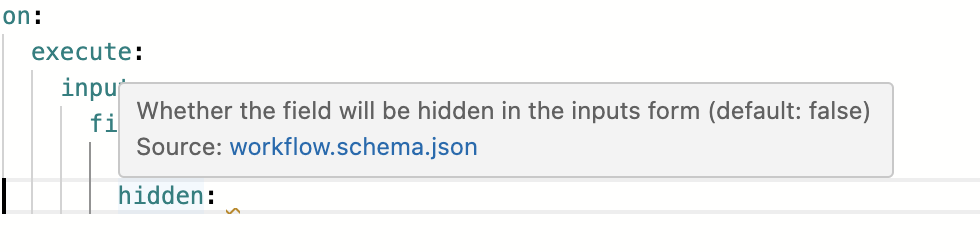
You can get information on what possible fields are allowed in a certain spot with the shortcut Ctrl+Space. Many fields, especially within jobs, have a description which you can read by hovering your cursor over the name of the field.
Ctrl+Space | Cursor Hover |
|---|---|
 |  |